

Foire aux questions
Avant de répondre à quelques unes des questions les plus fréquemment posées, nous vous laissons découvrir ces présentations sur les nuages arborés et leur utilisation en analyse littéraire:

Si vous n'avez pas trouvé de réponse à votre question, n'hésitez pas à me contacter.
Sur quelles tailles de corpus TreeCloud peut-il être utilisé pour construire des nuages arborés ?
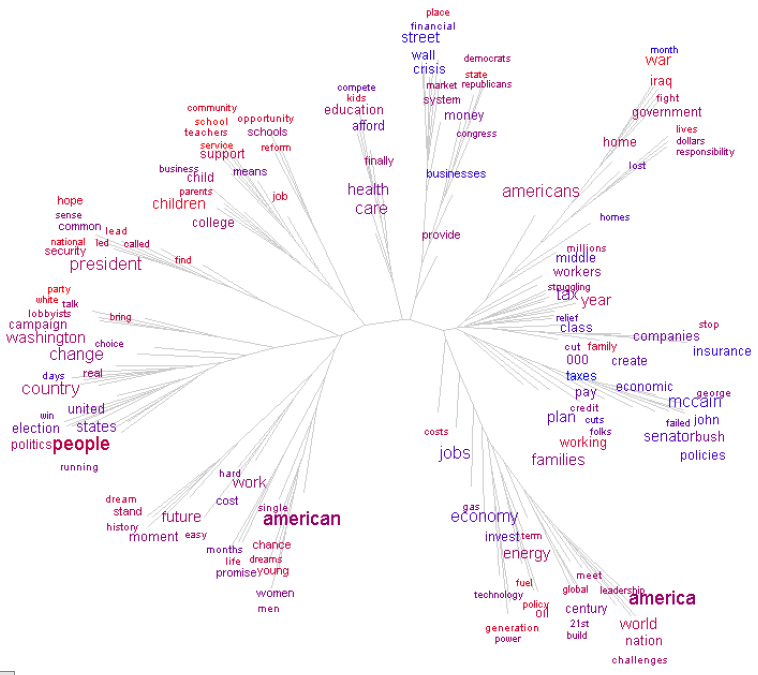
En fait la limite principale concerne le nombre de mots du nuage arboré (au dessus de 150 ça commence à être illisible sur un écran d'ordinateur, et long à calculer). La taille du corpus peut en revanche être très grande : le nuage arboré des 150 mots les plus fréquents parmi les discours de campagne d'Obama (plus de 350 000 mots) a par exemple été construit par TreeCloud (version Python, sur un PC portable équipé de Windows) en moins d'une minute.
{kind=link}
Quelles sont les utilisations possibles des nuages arborés ?
Leur principale utilité est de donner rapidement un aperçu du contenu d'un texte.
Notre présentation aux JADT 2010 montre comment il est possible de les utiliser pour une analyse plus en profondeur de textes, au sein d'une démarche textométrique. Le nuage arboré sert alors, comme le résume Delphine Amstutz, à :
- susciter, formaliser et étayer des hypothèses de travail (par exemple diapo 44, on montre comment il suggère l'étude du mot "amis" dans Cinna)
- comparer des textes selon leur représentation arborée (par exemple diapo 53, ils font apparaître l'utilisation contrastée du lexique amoureux dans Cinna et Othon)
- hiérarchiser l'utilisation d'autres outils textométriques (par exemple diapo 38, les mots qui apparaissent à des endroits intéressants dans le nuage arboré sont soumis au calcul des spécificités dans le discours de chaque personnage de Cinna avec Lexico 3)
- représenter les résultats de l'analyse (par exemple diapo 51, les mots spécifiques des pièces Cinna et Othon sont montrés dans un nuage arboré plutôt que dans la simple liste alphabétique, ou classée par spécificité, fournie par Lexico 3)
On nous a aussi suggéré (merci Jean-Baka ;) !) une utilisation lors de l'écriture de rapports ou de discours : en faire le nuage arboré permet de vérifier qu'on a rien oublié, que le texte est bien structuré, et que les messages principaux apparaissent clairement.
TreeCloud fonctionne-t-il aussi sous Mac ?
Actuellement il y a un problème avec les sauts de lignes dans les encodages de fichiers texte sous Mac. Nous travaillons sur ce problème et vous incitons à utiliser l'interface web de construction des nuages arborés (lien Créer ! en haut de la page) en attendant qu'il soit réglé.
Comment sont construits les nuages arborés ?
Nous détaillons le processus dans l'article avec Jean Véronis à IFCS 2009. Les formules statistiques utilisées pour déduire une distance sémantique entre deux mots à partir de leurs cooccurrences sont détaillées dans le manuel d'utilisateur de TreeCloud.
Comment utiliser TreeCloud avec d'autres logiciels de textométrie ou de traitement automatique des langues ?
Plusieurs interactions sont possibles avec Lexico 3. Elles sont illustrées dans cet ensemble d'exercices de travaux pratiques. Une utilisation d'Unitex pour repérer des expressions composés et les faire apparaître sans séparer les mots dans le nuage arboré est également décrite. Enfin, un travail est en cours pour permettre une intégration des nuages arborés dans TextObserver.
Comment utiliser les nuages arborés pour visualiser le champ lexical d'un mot en français ?
Vous pouvez utiliser les données de JeuxDeMots, qui propose un mot à des joueurs, en leur demandant d'associer d'autres mots qui sont en rapport. Techniquement, procédez de la façon suivante : entrez le mot voulu sur cette page, cliquez sur ok, et dans le cadre principal de la fenêtre, l'ensemble des mots voisins apparaît. Copiez le contenu de ce cadre, collez-le dans un éditeur de texte, recherchez/remplacez les séparateurs "/ /" par un "mot vide", par exemple "de" (qui ne sera pas compté lors du calcul du nuage arboré, mais servira de séparateur). Enfin, copiez-collez le résultat dans l'interface web de TreeCloud, en réglant la "taille de la fenêtre" à 2, pour que soient associés seulement les mots voisins. C'est du bricolage, certes, mais ça marche ! Et si vous voulez faire avec un système plus automatisé, vous pouvez toujours télécharger les données de JeuxDeMots, puis TreeCloud, et écrire un petit script pour lui envoyer les données voulues.
© 2007-2019 - Jean Véronis, Philippe Gambette, Jean-Charles Bontemps, Claude Martineau, S Deepak Srinivas








